Prerequisites
- You need a Postgres database that can receive incoming traffic from our IPs
15.188.105.163,15.188.215.105and35.181.129.14 - The associated database URL (should look something like
postgres://username:password@host.com/database)
Load your data
To get started, just go to the data loaders page in Hyperline. You should see an empty state.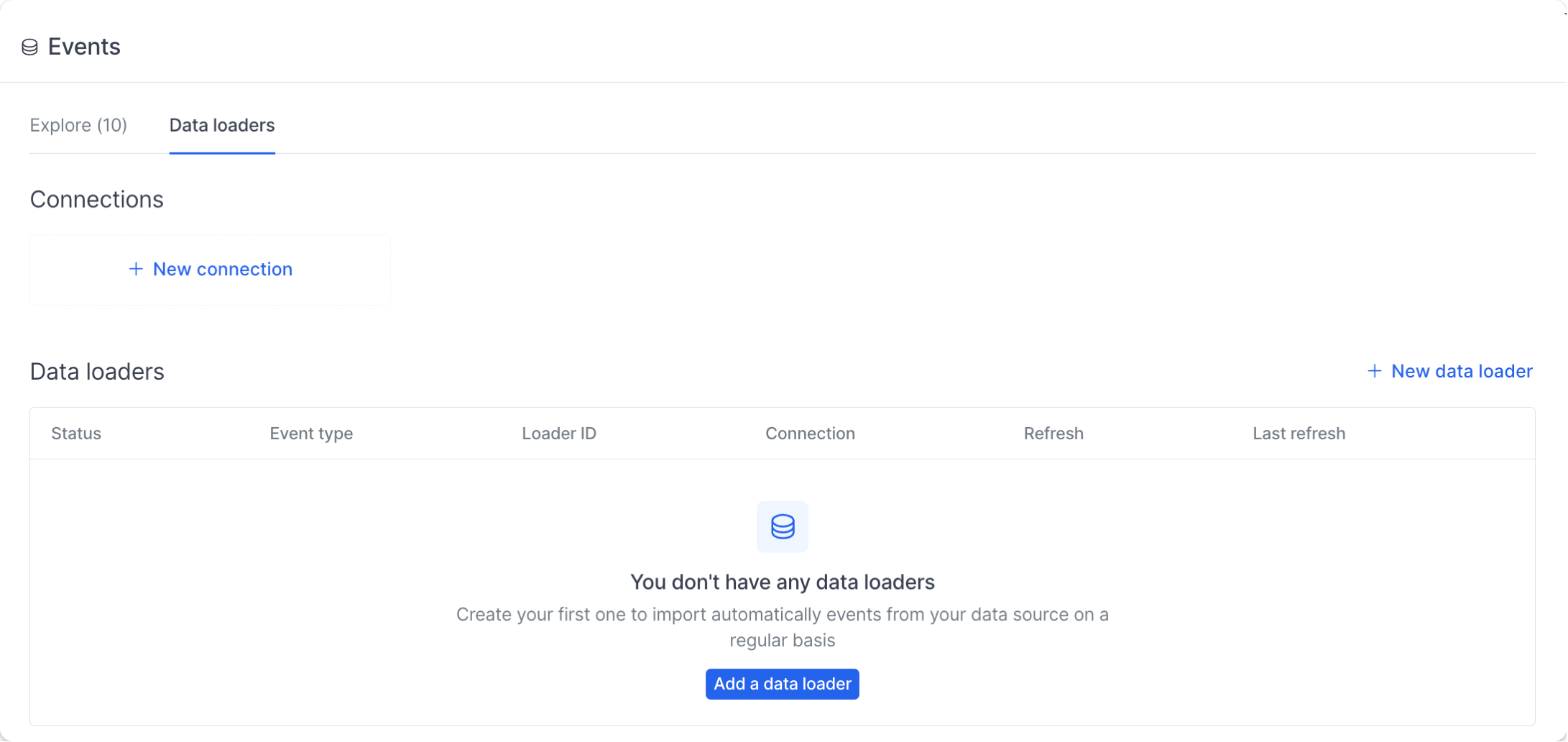
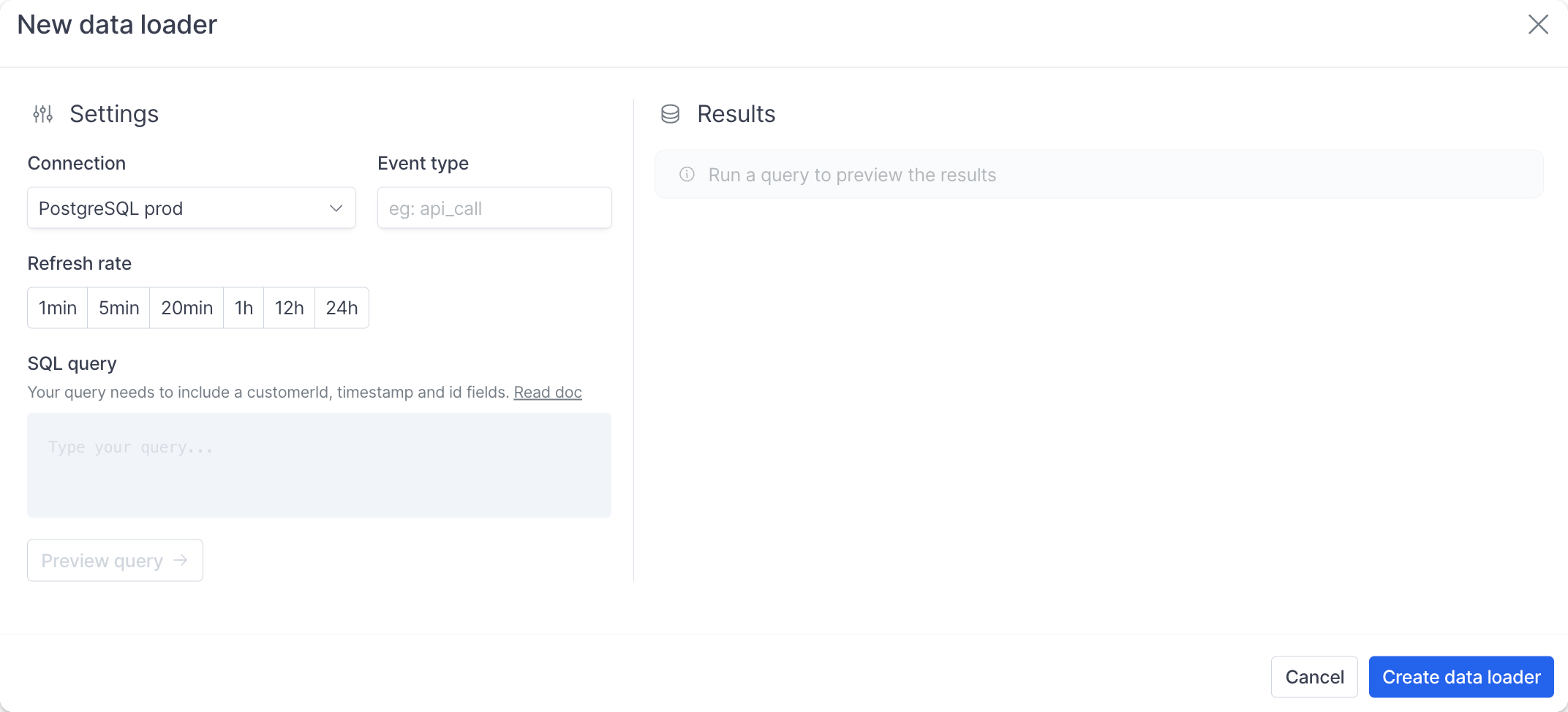
- Select a provider
- Give a name you’ll remember to your connection
- Enter the URL you got from the prerequisites
- Select the connection you just created
- Set an Event type for this query, it’s the identifier we’ll use later in the product to refer to the data from this query. It could be
api_callsoractive_usersfor instance - Select the refresh rate depending on your use case, to get started every hour is largely sufficient
Getting the SQL right
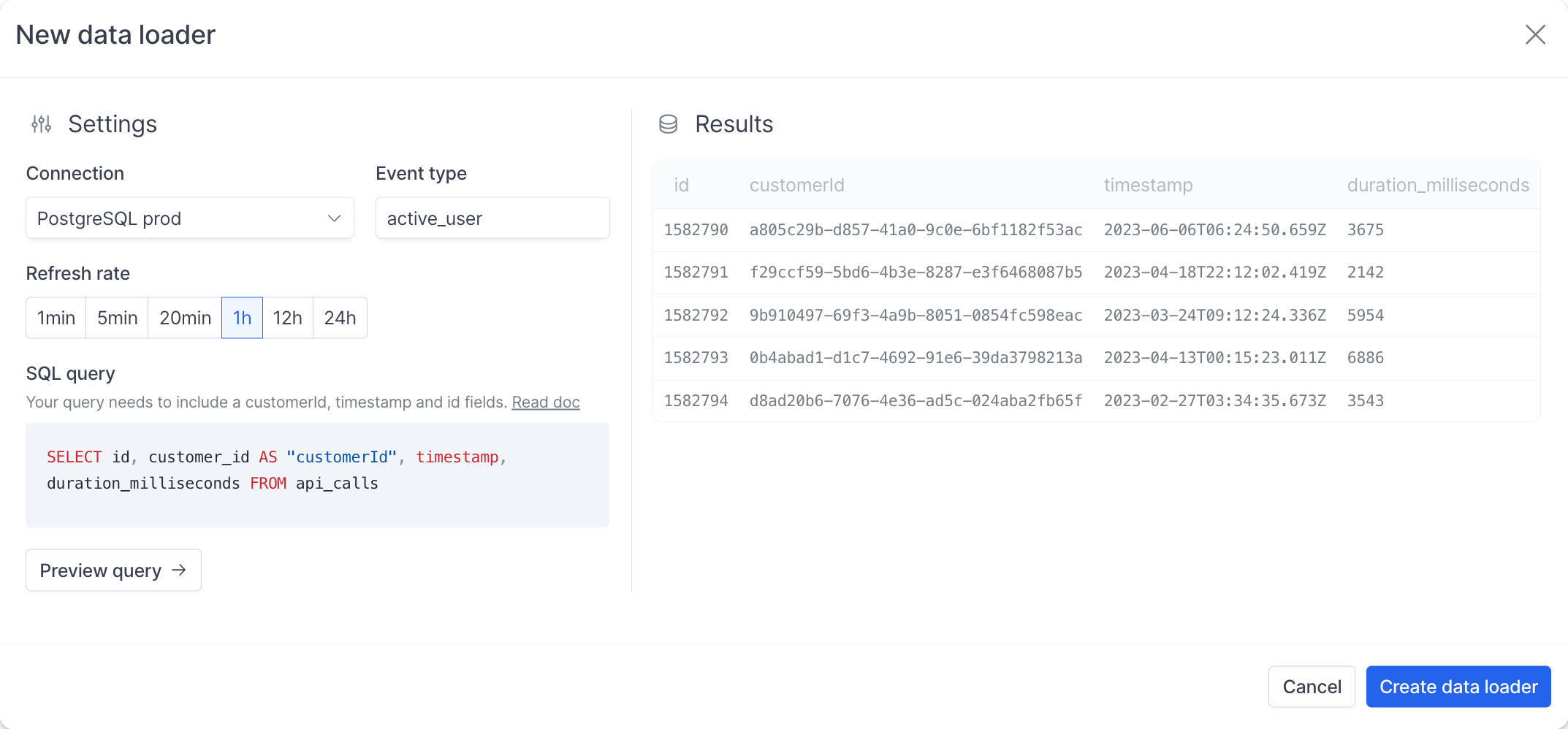
Now it’s time to start typing your query. Hyperline will need a few things from you and expect a specific format as the query output. We’ll need 3 fields to validate the query:timestamp— The date used to determine whether a record falls within a billing period. For example, if you bill monthly API calls, only events with a timestamp within the current billing cycle are included. This field is less critical if your pricing does not rely on periodic metering.customerId— The Hyperline ID or external ID of the customer. This field is used to associate each record with the corresponding customer.id— A unique identifier for the record (can be an ID from your system). Hyperline uses this field to de-duplicate and update records, so ensure it uniquely represents each record.
automatically_created that won’t be displayed by default in your customers list to avoid spam (but you can access them using the pending customers table).
Optionally, you can also return a customerName property so we add a name to the customer when creating it, which will make it easier for you to find them later.
To summarise, the minimum acceptable request looks like this
Updating records
Hyperline automatically updates existing records, we’re using a combination of the suppliedid and customerId and always keep the latest version. We don’t update customer names in Hyperline even if the name has changed, you’ll need to change it in the interface.
Deleting records
Hyperline doesn’t delete records automatically to avoid any issue, we recommend that you add adeletedAt field in the query that you set to something when the record is deleted. You’ll then be able to filter these records out in our pricing engine.