Prérequis
- Vous avez besoin d’une base de données Postgres pouvant recevoir le trafic entrant depuis nos adresses IP
15.188.105.163,15.188.215.105et35.181.129.14 - L’URL de base de données associée (qui devrait ressembler à
postgres://username:password@host.com/database)
Charger vos données
Pour commencer, rendez-vous simplement sur la page des chargeurs de données dans Hyperline. Vous devriez voir un état vide.
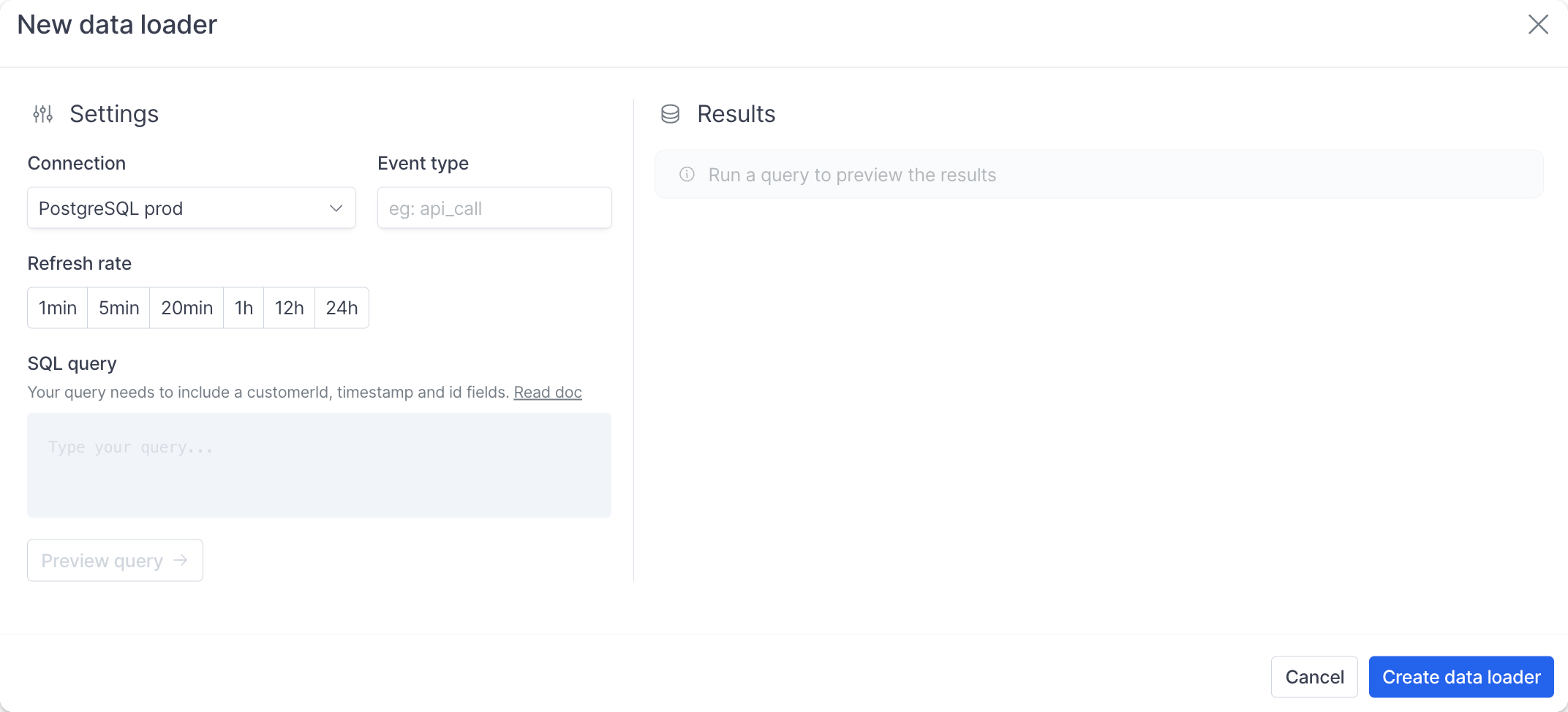
- Sélectionnez un fournisseur
- Donnez un nom dont vous vous souviendrez à votre connexion
- Saisissez l’URL obtenue dans les prérequis
- Sélectionnez la connexion que vous venez de créer
- Définissez un type d’événement pour cette requête. C’est l’identifiant que nous utiliserons plus tard dans le produit pour faire référence aux données de cette requête. Cela pourrait être
api_callsouactive_userspar exemple - Sélectionnez la fréquence de rafraîchissement selon votre cas d’usage ; pour commencer, toutes les heures est largement suffisant
Bien rédiger votre requête SQL
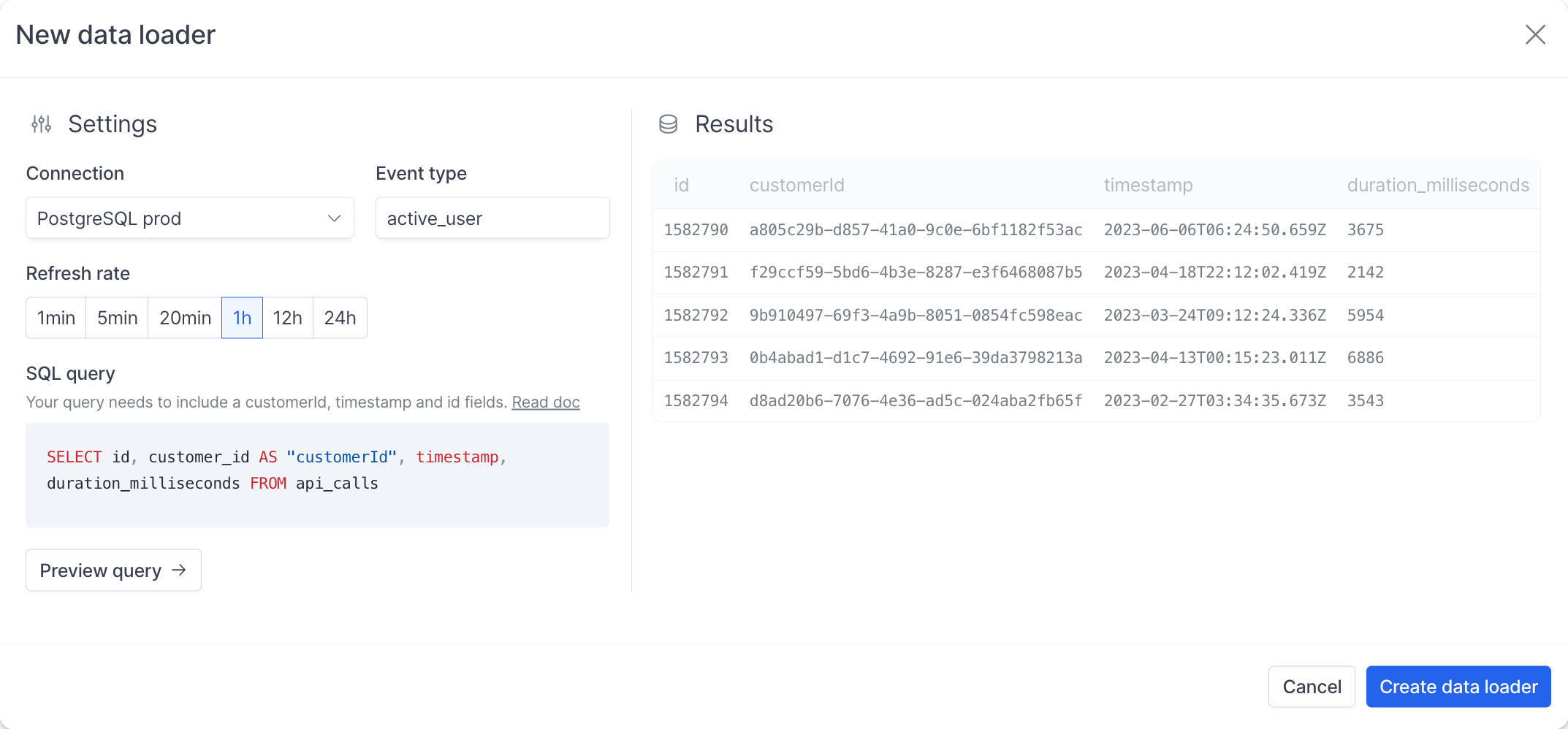
Il est maintenant temps de commencer à rédiger votre requête. Hyperline aura besoin de certaines informations de votre part et attend un format spécifique en sortie de la requête. Nous aurons besoin de 3 champs pour valider la requête :timestamp— La date utilisée pour déterminer si un enregistrement entre dans une période de facturation. Par exemple, si vous facturez mensuellement des appels API, seuls les événements avec un timestamp dans le cycle de facturation actuel sont inclus. Ce champ est moins critique si votre tarification ne repose pas sur un comptage périodique.customerId— L’identifiant Hyperline ou l’identifiant externe du client. Ce champ permet d’associer chaque enregistrement au client correspondant.id— Un identifiant unique pour l’enregistrement (peut être un identifiant de votre système). Hyperline utilise ce champ pour dédupliquer et mettre à jour les enregistrements, alors assurez-vous qu’il représente bien chaque enregistrement de manière unique.
automatically_created, qui ne sera pas affiché par défaut dans votre liste de clients pour éviter le spam (mais vous pouvez y accéder via la table des pending customers).
Vous pouvez également renvoyer une propriété customerName afin que nous ayons un nom à attribuer au client lors de sa création, ce qui facilitera son identification ultérieure.
Pour résumer, la requête minimale acceptable ressemble à ceci :
Mise à jour des enregistrements
Hyperline met automatiquement à jour les enregistrements existants. Nous utilisons une combinaison de l’id fourni et du customerId, et nous conservons toujours la dernière version. Nous ne mettons pas à jour les noms de clients dans Hyperline même si le nom a changé ; vous devrez le modifier dans l’interface.
Suppression d’enregistrements
Hyperline ne supprime pas automatiquement les enregistrements pour éviter tout problème. Nous vous recommandons d’ajouter un champdeletedAt dans la requête, que vous renseignerez lorsque l’enregistrement est supprimé. Vous pourrez ensuite filtrer ces enregistrements dans notre moteur de tarification.